On Reinforcement Learning for Large Language Models
A personal thinking on why reinforcement learning is vital for Large Language Models. [Updated 02/21]
Reinforcement Learning seems to be the right learning paradigm for AI (if we believe AI should think like us). Why? If we have a goal, we take action and get feedback, and then we learn from the feedback until we achieve the goal.
RL with Reward Signal
Arguably, the most convincing RL method so far is Alpha-Go/Zero
It utilizes models to generate proofs, uses reward oracle (formal language Lean) to generate feedback (right or wrong), and uses RL algorithms to optimize. It becomes successful by scaling up the model. Of course, there are many other components, such as the Formalizer network, but, as mentioned in David’s talk, it is essentially just RL at a large scale.
Another example is the ongoing Reinforcement Fine-Tunning (RFT) from OpenAI. This program allows developers to fine-tune existing models by providing a small set (dozens to thousands) of high-quality questions and reference answers. It says, “This technique reinforces how the model reasons through similar problems and improves its accuracy on specific tasks in that domain.” This is quite exciting, as we can use only a small number of samples (I think 10-1000 is small nowadays) to achieve amazing performance in advanced scientific tasks via RL algorithms.
More importantly, these are truly what humans do when facing a new task: We take action and get feedback, then “learn from the feedback” until we achieve our goal. This makes the idea of RL so natural for learning and improving the LLMs/AI. And then, different “learn from the feedback” will yield different RL algorithms.
Good RL algorithms for LLMs are akin to good learning habits in humans.
Offline RL vs. Imitation Learning
RL has yet to exhibit its full potential for LLMs. Existing post-training/fine-tunning methods are mostly “Imitation Learning” style. For example, the popular Direct Preference Optimization algorithm uses the Bradley-Terry model to construct the negative log-likelihood loss over the preference data—essentially an imitation learning approach.
What offline RL should do is stitch, effectively ‘stitching’ together (and also modifying) parts of the historical demonstrations to generate unseen, higher-quality ones. This idea is reminiscent of how we write papers—We have all the existing papers and leverage existing techniques together to generate new techniques/results.
It is natural that the same thing should happen to LLMs, which is offline RL (Of course, we should not go too far to forget the safety concerns, so adding a KL regularizer :)). There are some efforts in the simulated robotics tasks
RL without Feedback
In many situations, having feedback is not possible, and the RL loop contains only state and action. In this case, humans can still learn from previous responses/actions (historical data), reasoning about them, and coming up with an improved solution. It might be critical that LLMs also consider this perspective.
A Bright Future for RL
While RL has its limitations and challenges, its potential for advancing AI is immense. From improving LLMs to tackling complex problems like formal reasoning and beyond, RL offers a natural, human-like learning paradigm. Let’s focus on the bright side as we continue to explore its possibilities!
02/21 Update: RL significantly improves Math Reasoning on the GSM8K Data
DeepSeek-R1(-Zero) exhibits surprising capability for reasoning tasks such as Math and Coding
I also tried it myself, and here is my Setup:
-
Base Model: Qwen2.5-1.5B-Instruct;
-
Dataset: GSM8K; Training size: 7472 , Testing size: 1319.
RL Training:
-
Group Relative Policy Optimization (GRPO)
, GRPOConfig, GRPOTrainerfromtrl.trainer; -
Epoch: 1, Learning Rate: 1e-5;
-
8 H100s training for 5Hrs.
SFT Training:
-
Supervised Fine-tuning,
SFTTrainer, SFTConfigfromtrl; -
Epoch: 2, Learning Rate: 1e-6; The (Epoch, Learning Rate) pair is determined after hyperparameter search, This setup gives the highest accuracy on the test set;
-
4 H100s training for 10Mins.
Evaluation:
- Correct if
generated_answer == true_answer.
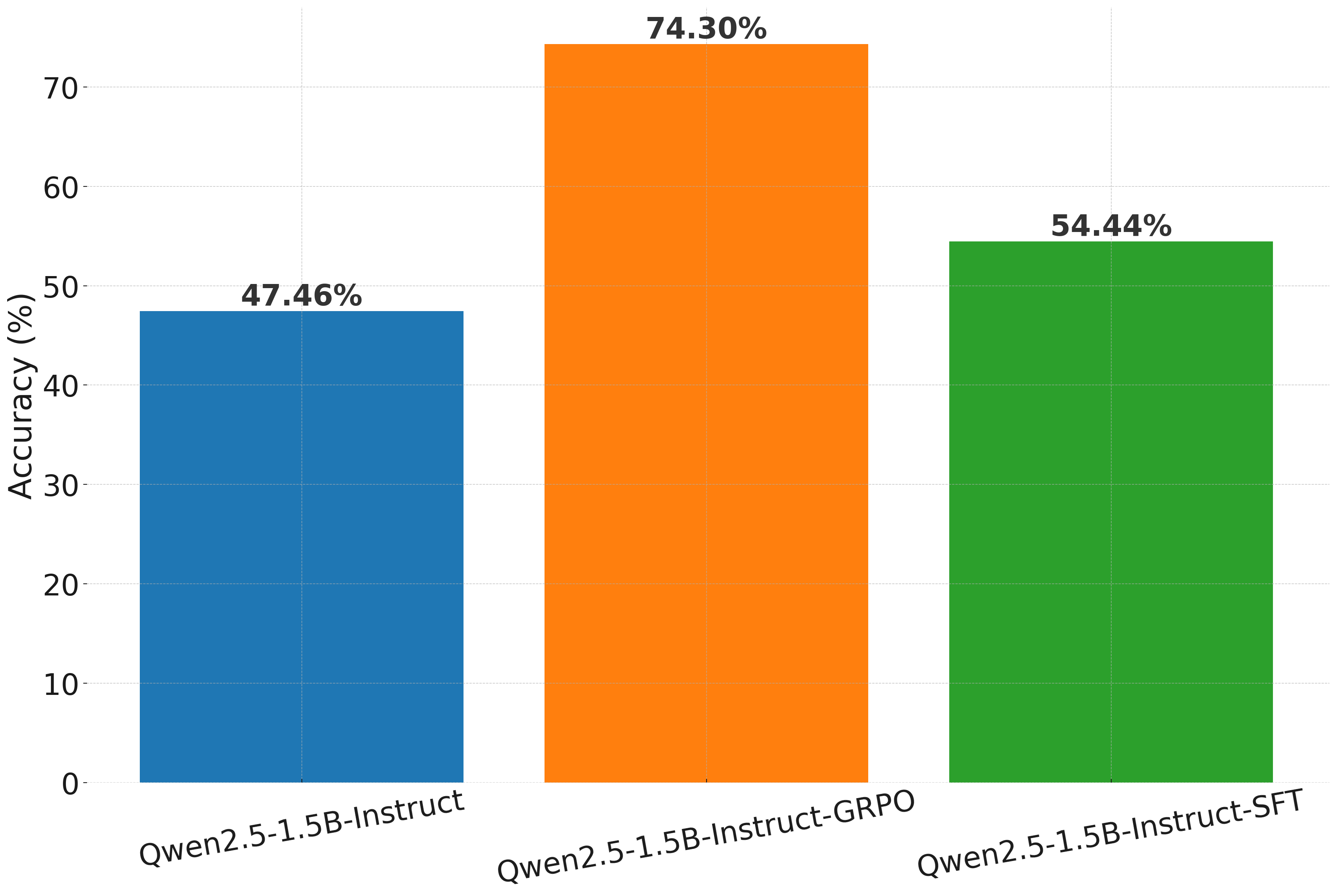
Takeaway: Reinforcement Learning significantly enhances the original model’s performance by 27% and surpasses the SFT approach by nearly 20%. This demonstrates RL’s strong potential for tackling challenging reasoning tasks! However, this improvement comes at the cost of increased computational overhead. The code is available here.